Die Google Search Console meldet: indexiert obwohl durch robots.txt-Datei blockiert. So löst du das Problem.
Die Suchkonsole ist eine der wichtigsten Google Tools für deine Website. Wenn du die Google Search Console eingerichtet hast, werden dir im Bericht Seitenindexierung mögliche Probleme aufgezeigt. Zu sehen ist, wann Google das Problem zum ersten Mal festgestellt hat und welche URLs davon betroffen sind. Die entsprechenden Seiten werden weiter unten aufgelistet.
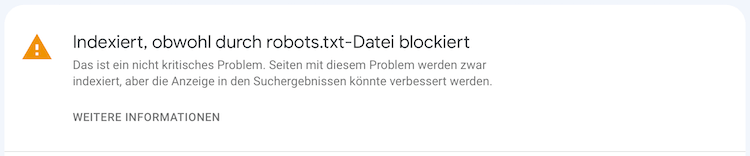
Was bedeutet “indexiert obwohl durch robots.txt-Datei blockiert”?
Die robots.txt-Datei ist für die Steuerung des Googlebots zuständig. Und damit für die Google Indexierung. Hierdurch erlaubst du dem Crawler, welche Verzeichnisse oder (Unter)Seiten, der Googlebot scannen darf oder nicht. Wenn z.B. ein Link auf die betroffene URL verweist, und diese später aber durch die robots.txt ausgeschlossen wird, dann kommt es zu dieser Fehlermeldung.
Indexiert obwohl durch robots.txt-Datei blockiert bedeutet, dass eine Seite schon in der Google-Suche gefunden werden kann. Allerdings wird das Crawling durch die robots.txt verhindert. Die Seite ist also aufrufbar, jedoch dürfte sie das eigentlich nicht. Diesen Widerspruch solltest du aufheben und Google klare Anweisungen geben.

So löst du das Problem
Damit Indexiert obwohl durch robots.txt-Datei blockiert aufgehoben wird, solltest du zunächst einen Blick in die robots.txt werfen. Diese liegt immer im Stammverzeichnis, z.B. https://www.deineseite.de/robots.txt.
Prüfe, ob darin Seiten oder Ordner aufgeführt werden, auf die der Crawler nicht zugreifen soll. Gesperrte URLs haben einen Disallow-Befehl, z.B.:
Disallow: /ordner_oder_URL/
Soll diese URL tatsächlich vom Crawling ausgeschlossen werden, geht das in Ordnung. Andernfalls lösche den Befehl. Prüfe die URL auch mit dem URL-Prüftool in der Search Console.
Ist das erledigt, kann es sein, dass Google etwas Zeit braucht, für die erneute Prüfung. Es kann also sein, dass sich das Problem von alleine löst.
Seiten, oder auch Bilder, solltest du besser per Noindex aus der Suchmaschine ausschließen. Alternativ bietet es sich eventuell an, dass entsprechende Verzeichnis durch einen Htaccess-Schutz zu sperren. Wobei das die Fehlermeldung Wegen nicht autorisierter Anforderung (401) blockiert auslösen könnte.
Normalerweise geht der Crawler davon aus, dass er alles durchforsten darf. Erst danach wird entschieden, was in den Suchindex darf. Werden vorher, durch die robots.txt aber bestimmte Dinge ausgeschlossen, meldet die Search Console Durch robots.txt-Datei blockiert.
Sollen einzelne Unterseiten nicht in der Suchmaschine auftauchen, sollten diese besser per Noindex ausgeschlossen werden. Früher war es noch möglich, Seiten über die robots.txt von der Indexierung auszuschließen. Davon ist Google mittlerweile abgewichen.
In RankMath z.B. kannst du das im jeweiligen Beitrag einstellen. Setze dazu im Reiter Erweitert den Haken bei Kein Index.
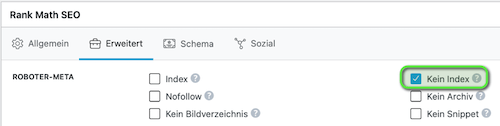
Dies trifft auch auf Bilddaten zu. Sollen Bilder nicht in den Suchresultate erscheinen, schreibe den Uploads-Ordner NICHT in die robots.txt. Sondern nutze hierfür die Funktion in RankMath. Gehe dazu in WordPress auf Medien. Wähle das entsprechende Bild aus und klicke ganz unten auf Weitere Details bearbeiten. Unter dem Bild siehst du wieder das Menü von RankMath. Markiere das Häkchen bei Kein Index.
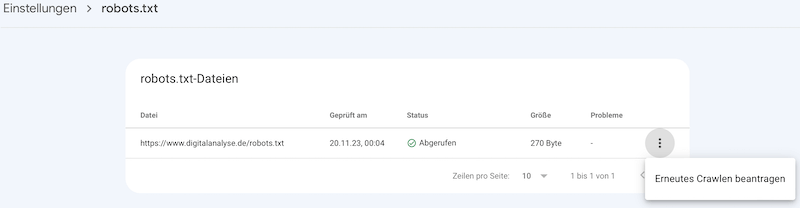
Problem gefunden? Dann lade die überarbeitete Datei auf den Server in das Stammverzeichnis. Reiche danach die neue Datei in der Google Search Console ein. Gehe dazu auf Einstellungen, in der Mitte bei robots.txt ganz rechts auf Bericht öffnen.
Klicke auf das 3-Punkt-Menü ganz rechts, um die robots.txt erneut zu crawlen.
Wechsle anschließend zurück in die Google Search Console, in den Bericht Seitenindexierung. Klicke dann auf Fehlerbehebung überprüfen.
![]()
Beachte, dass Google die robots.txt außerdem 24h zwischenspeichert.